

I’ve spent much of my career as a data scientist evaluating the impact of new technology. Whether helping cities optimize bus schedules or companies plan EV charging infrastructure, the underlying questions were always the same:
- Was this investment worth it?
- Are the impacts measurable?
- Can we repeat the solution and scale the outcomes?
In healthcare, those questions are much harder to answer — especially as technologies like AI enter the picture. Hospital leaders are under growing pressure to integrate AI solutions across their organizations. Yet, despite the rapid proliferation of healthcare AI vendors, only 30% of AI projects ever make it past the pilot stage.
For hospital operational and innovation leaders, the core challenge is not finding AI solutions, it’s reducing the risk that those initiatives fail to deliver and scale. Before deploying any AI tool, leaders need confidence that it will produce measurable results in real-world operational environments.
Why proving AI outcomes in hospitals is so difficult
Hospital operations are inherently dynamic — especially in operating rooms. Fluctuations in staffing, room availability, case mix, seasonality, and even construction projects can all affect performance, making it difficult to establish a stable baseline for comparison.
On top of that, most hospitals rely on manually-entered EHR data to assess performance. That data is often incomplete, delayed, or inconsistent — making it difficult to understand what actually changed, let alone why. Without a reliable view of workflow before and after implementation, evaluations of AI tools may rely on anecdotal evidence or individual customer stories that don’t pass the control test.
Learn how Apella is associated with measurable case volume increases across hospitals.
Read the full analysis
What it takes to measure AI outcomes in the OR at scale
Reducing risk when adopting AI in the OR requires outcome evidence built on three elements that often go missing:
- Objective Operational Data. Accurate measurement of OR impact depends on reliable, granular data — such as when patients enter rooms, when cases start and end, turnover durations, and sources of delay. These details are difficult to capture consistently through manual documentation alone.
- A Credible Pre-Implementation Baseline. Without historical performance data, it’s impossible to distinguish meaningful improvement from normal operational variation.
- Analytical Methods that Account for Variability. Evaluations must control for confounding factors like seasonality, staffing levels, and case mix to avoid misattributing routine fluctuations to new technology.
When these elements are in place, it becomes possible to evaluate AI outcomes in a way that is both rigorous and comparable across hospitals.
Real-world evidence at scale
To confirm and measure impact across hospitals, Apella conducted a longitudinal outcomes analysis looking at changes in surgical case volume in 18 hospital OR sites. This analysis was possible because the foundations required for rigorous measurement are built into how Apella is deployed:
- Objective OR workflow data captured through ambient sensing
- A credible pre-implementation baseline drawn from historical EHR data
- Analytical methods developed by a dedicated data science team
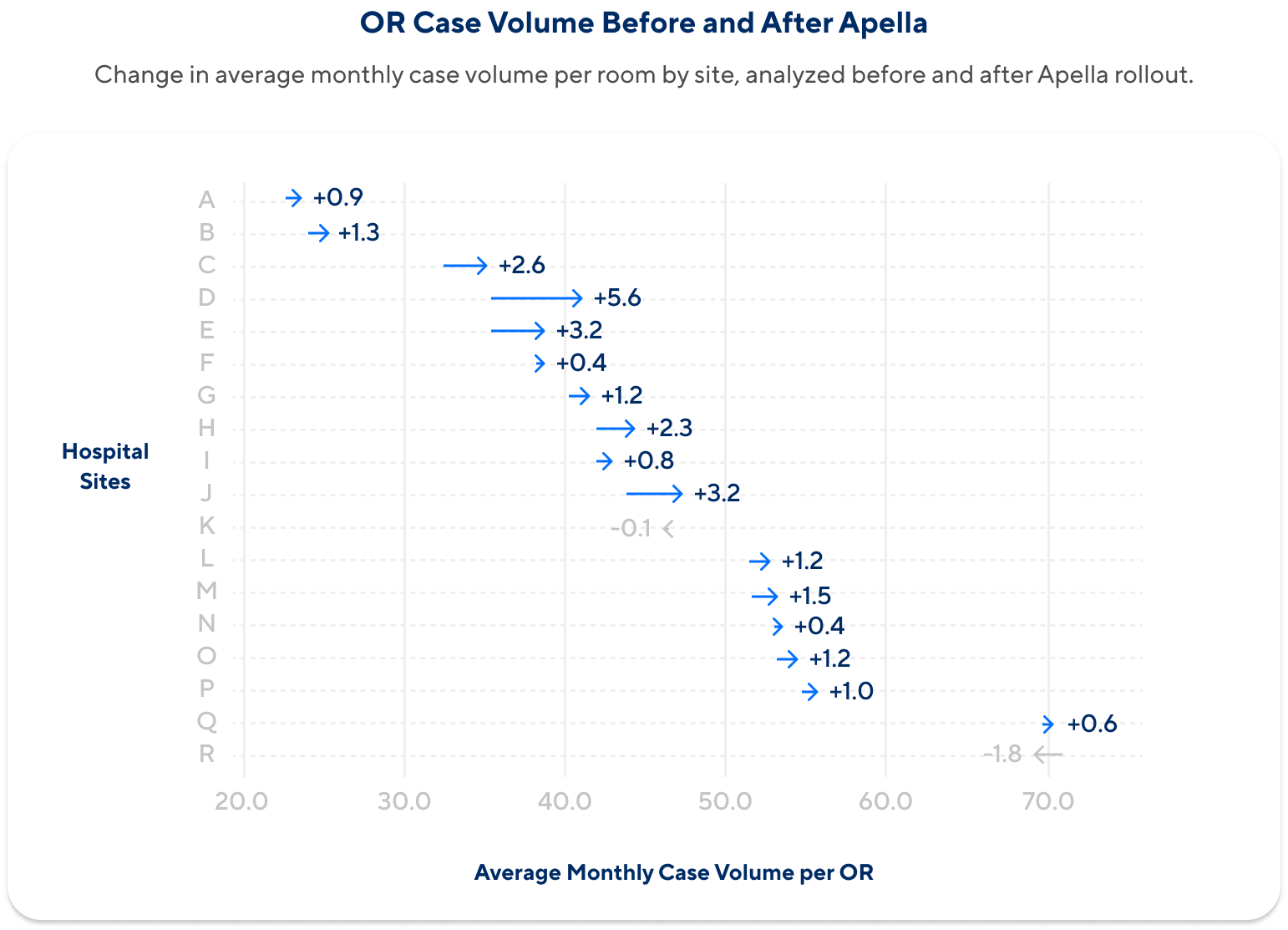
The outcome analysis evaluated case volume on a per-OR, per-month basis before and after adoption, using a regression-based framework designed to account for seasonality and other confounding factors. The results showed a consistent pattern across hospital sites after rolling out Apella:
- Nearly 90% of sites showed an increase in case volume
- Average increase of two additional cases per OR per month
- This corresponds to an estimated 270 additional cases per year, or an average 4% increase in surgical case volume
Why this matters for hospital leaders
For hospital leaders evaluating AI technologies, the central question isn’t whether AI is necessary, but how to adopt it with confidence. In complex environments like the operating room, outcome evidence drawn from multiple hospitals provides a critical signal when assessing which solutions are most likely to deliver measurable impact at scale.