

As ambient AI becomes more embedded in hospital operations, leaders evaluating multiple vendors should be asking key questions about the quality of the underlying technology: What data was the model trained on? What performance metrics are publicly reported? Has it been independently validated? Does performance hold at scale?
This post examines what those standards look like in practice, based on a peer-reviewed study evaluating the quality of Apella’s ambient AI across a range of hospital operating room environments.
Ambient AI for real-time decision-making
In high-cost environments such as the operating room, efficient decision-making depends on the quality of the data informing it. Yet many perioperative teams still rely on manually-entered EHR timestamps, which are often delayed or inconsistently recorded.
Apella’s ambient AI uses computer vision to automatically detect key OR events as they occur, such as the patient entering the OR or being draped. These timestamps are immediately shared across perioperative teams, reducing communication lag and enabling decisions to reflect what is actually happening in the OR — not what was entered into the EHR several minutes later.
This real-time visibility allows teams to intervene proactively to prevent delays, adjust staffing, and optimize capacity.
Transparency through peer-reviewed evaluation
The performance of Apella’s ambient AI system was evaluated in a peer-reviewed study published in BMJ Health & Care Informatics. The study assessed the model’s ability to accurately detect and segment key perioperative events across the surgical workflow. Methodology, performance metrics, and study limitations were fully disclosed through the peer-review process.
For hospital leaders evaluating AI solutions, independent peer review provides an objective reference point. It introduces external accountability and methodological rigor into performance claims, reducing reliance on vendor-produced case studies or marketing materials alone.
To our knowledge, Apella is the first commercial ambient AI OR platform to publish peer-reviewed model performance results based on active, real-world hospital use at scale.
Verified ground truth across 100,000+ surgical cases
The evaluation measured model performance across more than 100,000 real-world surgical cases, allowing assessment of whether performance holds at scale across different hospitals and providers.
Every validation data point was manually quality-assured by surgical domain experts before being established as ground truth. This level of verification ensures that reported performance reflects observed perioperative events rather than delayed, incomplete, or inconsistently recorded documentation. For leaders evaluating enterprise technologies, this distinction directly affects the reliability of downstream operational decisions.
Learn how Apella is associated with measurable case volume increases across hospitals.
Read the full analysis
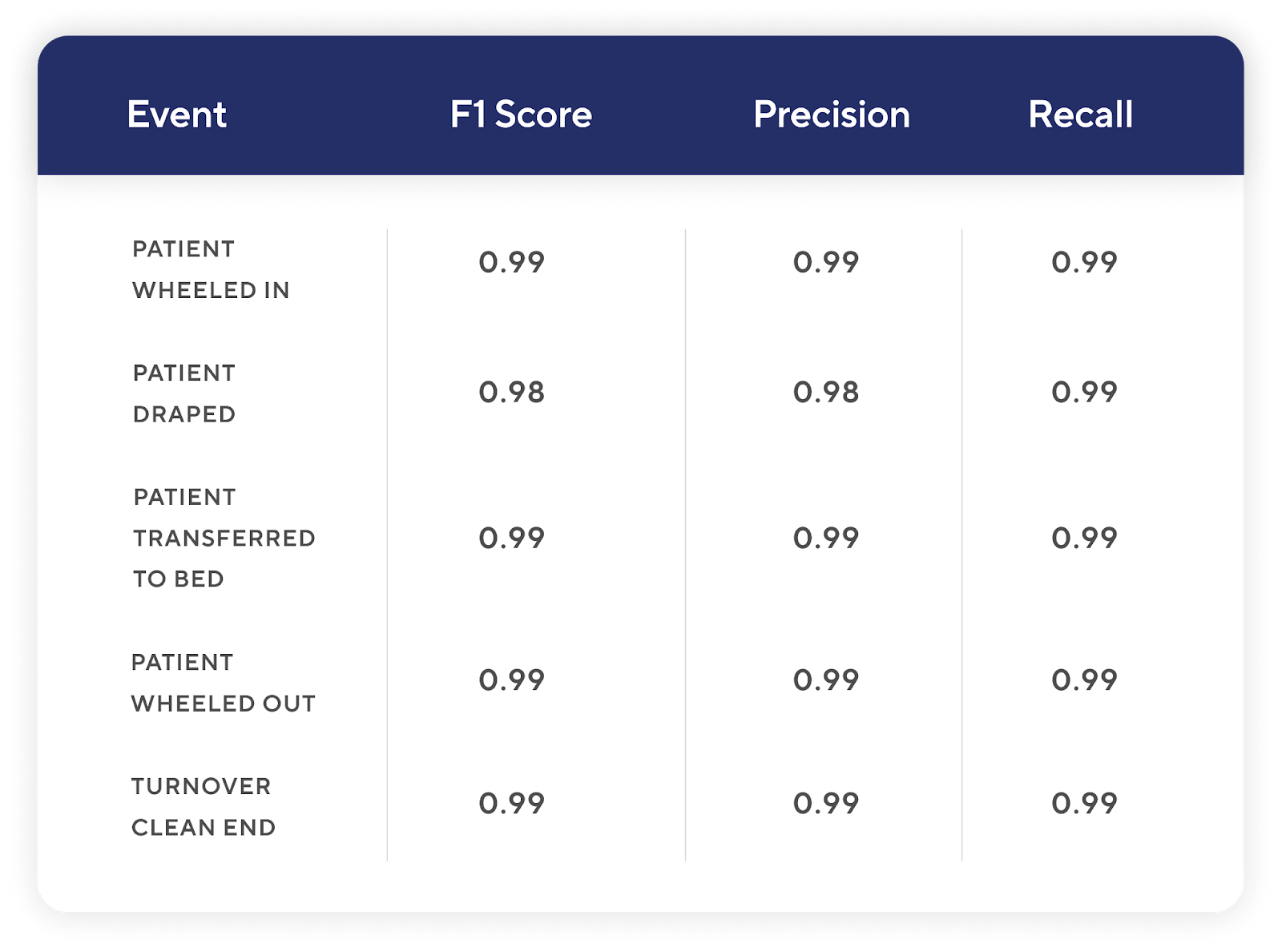
Decision-grade performance at F1 > 0.98
Model performance across key perioperative events was measured using the F1 metric, widely regarded as the industry standard for evaluating AI systems that drive operational decisions.
In healthcare environments where AI outputs influence key operational decisions, the performance threshold must be high:
- F1 ≥ 0.98: Necessary for real-time decision-making for individual cases
- F1 0.95–0.97: Generally appropriate for operational decision-making
- F1 0.90–0.94: Acceptable for higher-level aggregate analysis
- F1 < 0.90: Not recommended for production deployment
Across all reported perioperative events, Apella’s F1 scores exceeded 0.98, demonstrating strong alignment between automated detection and verified ground truth. At this level of performance, ambient AI moves from supportive to decision-grade insights, capable of driving real-time operational management in high-stakes surgical environments.
Revealing efficiency opportunity beyond the turnover
Beyond validating model performance, the study reframed where surgical efficiency opportunity truly exists.
Historically, many hospitals have concentrated improvement efforts on turnover time. However, the findings showed that turnover time accounted for only 24% of total OR case time. The remaining 76% was distributed across other perioperative phases — including anesthesia induction, patient preparation, active surgery, and wrap-up.
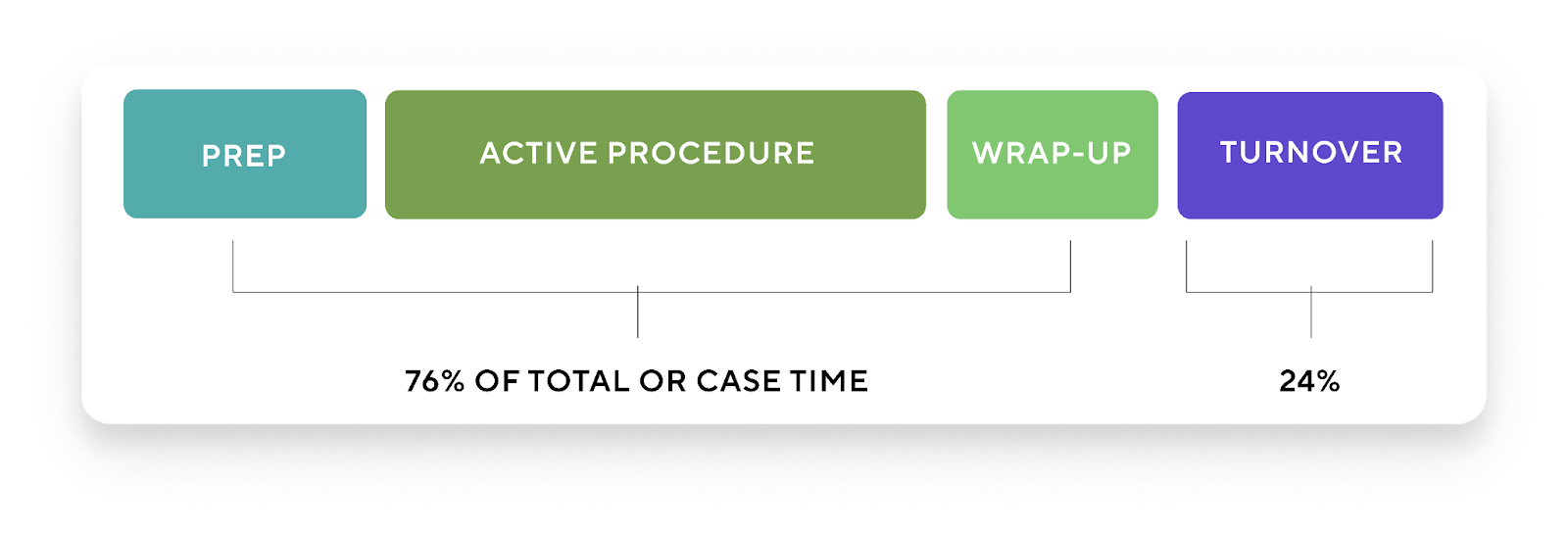
For executive leaders focused on throughput, margin, and capacity, this has strategic implications. If the majority of variation occurs outside of turnover, then concentrating improvement efforts solely on turnover inherently limits impact. Accurate phase-level detection enables a broader, data-driven understanding of where variability — and therefore opportunity — exists across the full surgical workflow.
From validated quality to measurable impact
This study demonstrates that computer-vision–based ambient AI can detect and segment perioperative workflows with high accuracy, at scale, under real-world operating conditions.
For hospital leaders evaluating enterprise technologies, validation is foundational — but it is not sufficient. The critical question is whether decision-grade accuracy translates into measurable operational and financial impact.
The evidence suggests that it can. In a separate large-scale analysis, Apella was associated with an average increase of two additional cases per OR per month, increasing patient access without physical OR expansion. Read the full analysis here.